弊社ではアンプリコンシーケンス解析のデータ解析において、QIIMEのバージョンはQIIME2を標準とすることにいたしました(2019年5月20日受注分から)。すでにお見積り済の方には、受注時にQIIME1またはQIIME2のいずれをご希望かを確認した上で進めさせていただきます。
QIIME1とQIIME2は何が違う?
一番大きな違いは代表配列の決定方法です。
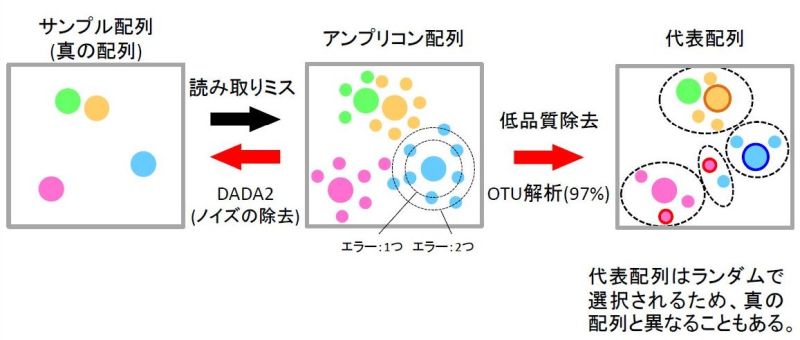
QIIME1のOTU法(上図右側)では代表配列がランダムに選ばれるため、解析ごとに代表配列が異なる可能性があります。また、シーケンサーのエラーに由来する配列を一つのOTUとしてまとめてしまう可能性もあります。
一方、QIIME2ではシーケンサーのエラーを補正するDADA2モデル(上図左側)が利用されており、上述した従来バージョンの問題点が解決されています。リリース自体は少し前なのですが、微生物関係の研究者の間でも支持されてきていること、環境DNAの解析パイプラインでも導入されていることからバージョンアップすることにしました(自社検証作業済)。
DADA2の導入については環境DNAの解析でも問題点の解消に役立っています。従来のOTU法だと同種として判定された複数のデータが種内多型なのかシーケンサーのエラーに起因するのかがわかりませんでした。また代表配列がランダムなため、1-2塩基しか違わない生物種の場合、誤同定の可能性がありました(例:ウグイをマルタウグイと推定しまう、あるいはその逆。)。
以前のアナウンスでは4月1日以降QIIME2を標準とさせていただくとしておりましたが、数か月間の試験運用でいくつかのバグが見つかり、その対策に時間を要していました。
実験の継続性ということもありますので旧バージョンでの対応も可能でございます。旧バージョンと両方での解析の場合は500円/1サンプルの追加料金をいただきます。